CribML, Part 1
As a parent of an infant, one thing you quickly learn is that they wriggle all the time, even when they are supposedly asleep. My little one likes to do laps around his crib when he’s fast asleep, regularly doing 360 degree turns as he does so. Like many parents, we have a baby monitor to keep an eye on him whilst we are in another room and he’s sleeping (or not, as the case may be). What’s annoying about these products is that they usually don’t tell you anything more than “there’s motion or noise!” which can make it tedious for notifications and you resort to essentially watching him all the time on the monitor.
While on paternity leave I found this annoying, so started working on this project: CribML. The idea is that we can have a system learn what the baby is doing, so the parents are only notified when there is some actionable behavior that needs assistance. To achieve this, I decided to give Apple’s relatively recent ML suite of tools a go instead of the more broadly used PyTorch / TensorFlow, as i’d be running this application on my phone and / or on my mac laptop. Specifically, here i’m using CreateML for training and exploration of the model, which then gets exported into a model file that can be utilized with Apple’s CoreML, which I plan to utilize using Swift UI.
Having never used these tools (but being familiar with similar ones) I have to say, it was very easy to get up and running. In order to do training, I needed at least 50 examples - I went about collecting contents from the historical camera video and annotating them appropriately. For the annotation steps, I used RectLabel Lite and just worked through the training set adding annotations. To make it easy to start, I decided to just tackle sleeping positions (front, back and side), with the intention of adding various awake behaviors later (e.g. scratching, awake, crying). The nature of babies makes it easier to find more content for them sleeping than it does when they are unhappy / awake!
With CreateML you only need throw all your images into a single folder, along with a JSON file describing the labels and x/y position of the bounding boxes are you’re away to the race. RectLabel Lite can export the relevant JSON file for you from your annotated set. After doing this, you conduct training:
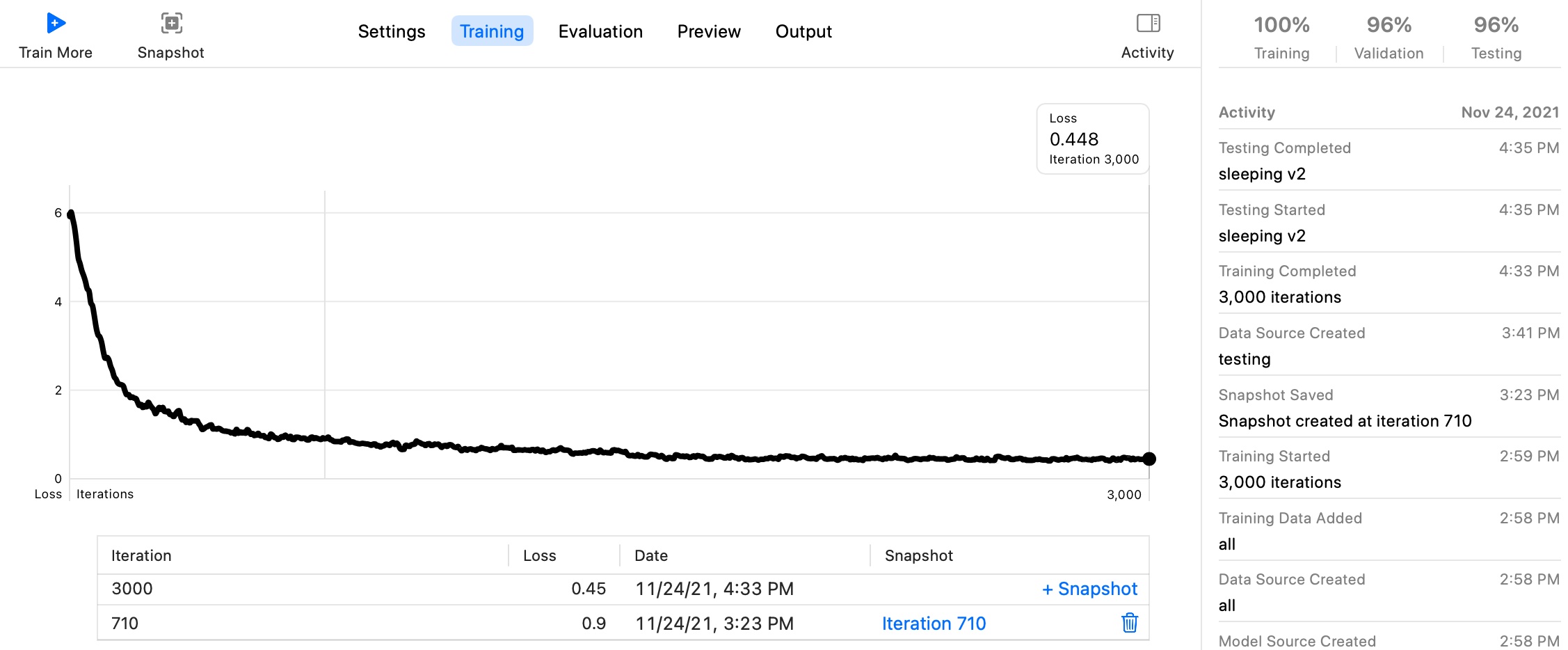
After approximateily an hour (on a 2021 Macbook Pro M1) the model converged with relatively good accuracy. Here’s a couple of output examples (child’s face redacted for privacy):
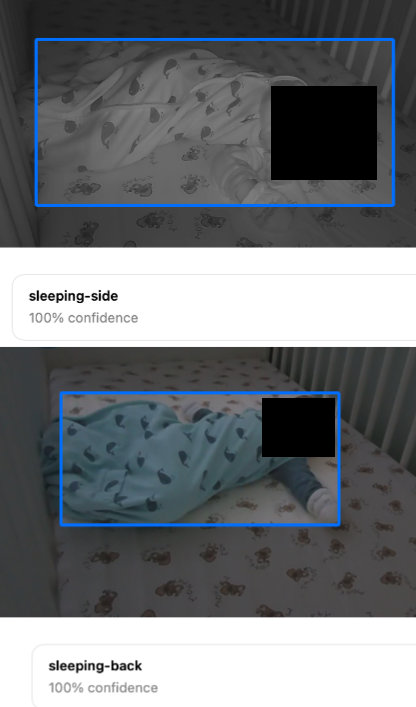
For 67 examples, this is pretty good and as yet, we’ve written no code to speak of. As it would turn out, the network being used under the hood is YOLOv2 which is by default a pretty capable image detection net and so we were able to quickly come to something functional.
In the next part of this series i’ll be utilizing CoreML to load and apply this model dynamically to content coming from the camera, wrapped up in a small application UI.