Envoy with Nomad and Consul
The past couple of years of my professional life have been spent working in, on and around datacenter and platform infrastructure. This ranges from the mundane activities like log shipping, through to more exciting areas like cluster scheduling and dynamic traffic routing. It’s certainly fair to say that the ecosystem of scheduling, service mesh and component discovery - along with all the associated tools - has absolutely blossomed in the past few years, and it continues to do so at breakneck speed.
This pace of development can in my opinion largely be attributed to the desire to build, evolve and maintain increasingly larger systems in parallel within a given organization. If we look back perhaps to the start of the last decade, monolith applications were the norm: deploying your EJB EAR to your Tomcat application server was just how business got done. Applications were typically composed of multiple components from different teams and then bundled up together - the schedules, features and release processes were tightly coupled to the operational deployment details. In recent years, organizations have - overwhelmingly - moved to adopt process and technologies to enable teams to produce services and projects over time in a parallel manner; velocity of delivery can massively affect the time to market for a broader product, which in many domains has a very tangible value.
The layers in this new stack change the roles and responsibilities of system building quite significantly; consider the diagram below, outlining these elements, and annotated with their associated typical domain of responsibility.
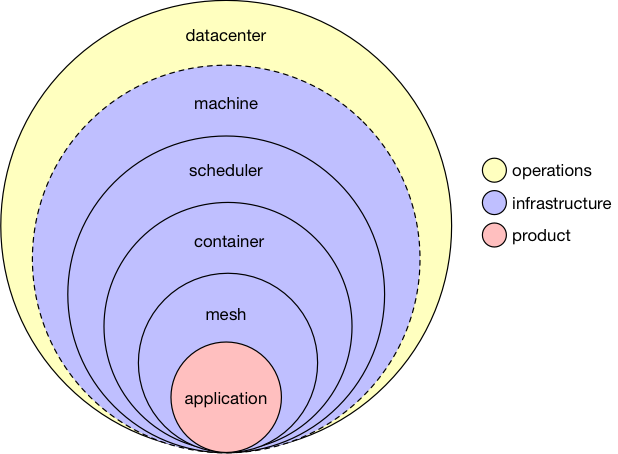
Had I been diagraming this a decade ago, it would have been all yellow except for the engineering related to the specific business product (shown here in red). Instead of that, what we see here is an effective and practical commoditization of those intermediate components: operations staff are largely removed from the picture, freed up to solve hard problems elsewhere, whilst platform-minded engineering staff provide a consistent set of tools for the wider product engineering groups - everyone wins!
In this article, I’ll be covering three of the hottest projects that are helping usher in these organizational changes, and enabling teams to ship faster and build larger systems out of small building blocks, often solving long-time problems with infrastructure engineering:
The next few sub-sections review these tools at a high-level - feel free to skip these if you’re already familiar or don’t want the background.
Nomad
Nomad hit the scene in the middle of 2015, and for the most part has been quietly improving without the fanfare or marketing of other solutions in the scheduling space over the last two years. For the unfamiliar reader, Nomad is a scheduler that allows you to place tasks you want to run onto a computer cluster - that is a selection of machines which run the Nomad agent. Unlike other scheduling systems in the ecosystem you may be familiar with, Nomad is not a prescriptive PaaS, nor is it a low-level resource manager where you need to provide your own scheduler. Instead, Nomad provides a monolithic scheduler and resource manager (see the Large-scale cluster management at Google with Borg paper for a nice discussion on monolithic schedulers) which supports the handful of common use cases most users would want, out of the box.
For the purpose of this blog post, the exact runtime setup of Nomad doesn’t really matter that much, but i highly encourage you to read the docs and play with it yourself. One feature I will point out which I think is awesome: out of the box integration with Vault. If you want dynamic generation of certificates and other credentials for your tasks, this is so useful, and its nice to have a solid, automated story for it that your security team can actually be happy signing off on.
Consul
Once you start running more than one system on Nomad, those discrete systems will need a way to locate and call each other. This is where Consul comes in. Consul has been around since early 2014, and sees deployments at major companies all around the world. Consul offers several functional elements:
- Service Catalog
- DNS Provider
- Key Value storage
- Serf-based failure detector
Reportedly, there exist Consul meshes in the field that run into the tens of thousands of nodes! At this point the project is battle hardened and more than ready for production usage. The feature we’re most interested in for the purpose of this article is the service catalog, so that we can register deployed systems, and have some way to look them up later.
In order to look up services in the catalog, using DNS is a no-brainer for most systems, as DNS is as old as the internet and practically every application already supports it. Generally speaking, i’d recommend having a Consul cluster setup so that you have a delegate domain for DNS, such that consul “owns” a subdomain from whatever your main TLD is. This ends up being super convenient as you can reference any service with a simple DNS A-record (e.g. foo.service.yourdatacenter.yourcompany.com), which lets you integrate all manner of different systems even if those systems have no idea about Consul, with zero extra effort.
When you deploy a system with Nomad you have the option for it to be automatically registered with Consul. Typically, when when your container exposes ports you wish to access when its running, some re-mapping is required as - for example - two containers cannot expose and occupy port 8080 on a given host. In order to avoid port collision, Nomad can automatically remap the ports for you so the ports bound on the host are dynamically allocated; for example, 65387 maps to 8080 inside the container. This quickly becomes problematic because each and every container instance will have a different remapping depending on which Nomad worker it lands on. By having Nomad automatically register with Consul, you can easily lookup all the instances for a service from the catalog. This works incredibly well because as a caller, you don’t then need any a-priori information about the IP:PORT combinations… its just a DNS query or HTTP request.
Envoy
In September 2016, Lyft open-sourced Envoy. On the face of it, Envoy may appear to be a competitor to something like Nginx - Envoy however does much more than a simple proxy. Envoy fills an emerging market segment known as the service mesh, or service fabric. Every in-bound and out-bound call your application makes - regardless of if you run it; containerized on a scheduler, or on bare metal - is routed via an Envoy instance.
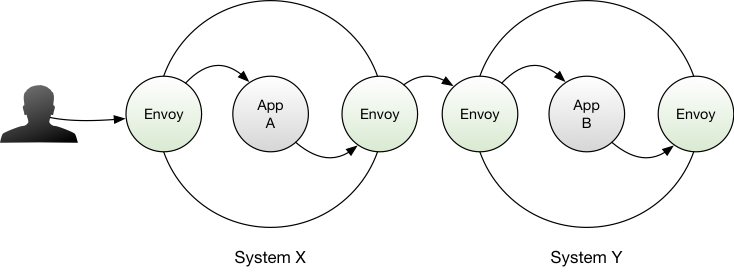
This might seem counter-intuitive - applications have traditionally handled everything related to making requests, retries, failures and so on… and this has largely worked. However, if the application itself is handling all the retry, monitoring, tracing and other infrastructure plumbing required to make a viable distributed system, then as an organization you have a tricky trade off to make:
- Preclude a polyglot ecosystem because the cost of re-implementing all that missing critical system insight, or:
- Pay a high operational cost by having to support these intricate systems in many different languages, and have to retain staff expert enough in all these languages to solve problems over time.
Envoy alleviates this problem by providing a hardened side-car application that handles retries, circuit breaking, monitoring and tracing - your applications just make “dumb” requests. You then only have one way to operationally deal with the ecosystem across your entire distributed system. Requests are retried, traffic can be shaped and shifted transparently to the caller, throttling can be put in place without modifying applications in the event of an outage… the list goes on. Even organizations that have strived for homogeneity in their software ecosystem inevitably find that other technologies are going to creep in: are you going to build your marketing website using Rust and re-implement the world needed to render Javascript to a browser? No. You’ll likely end up node.js, or - god forbid - some PHP… shudder. But, you get the point dear reader: its inevitable even for those with the best of intentions, and in this frame Envoy quickly becomes attractive.
Usage
For clarity, i’m going to start out with the following reasonable assumptions so that we don’t have to waste time discussing them later:
-
Consul and Nomad are clustered with a minimum of at least five nodes. This allows you to conduct rolling upgrades without outages or split brains.
-
You setup Consul using DNS forwarding so you can just blindly use Consul as your local DNS server without having to futz with
/etc/resolve.confor the like (which can get hairy in containerized setups). -
Nomad agent and Consul agent are run on every host. They have full, unadulterated network line of sight to their relevant servers on all ports (assuming a perimeter security model, without micro segmentation of the network).
These designs are suggestions, and there are potentially awkward trade-offs with any design you choose to implement in a system. Before copying anything you see here, make sure you understand the trade-offs and security considerations.
The first thing to consider is what elements of the infrastructure one wants to install on the underlying host: do you want to run monitoring from the host? Or embed it? Do you want a per-host Envoy or an embedded one? Honestly, there are no slam-dunk solutions, and as mentioned all come with their own particular flavor of down-sides, so we’ll walk through both a host-based model and an embedded model for Envoy.
Clusters and Discovery
Envoy has the concept of “clusters”… this is essentially anything Envoy can route too. In order to “discover” these clusters, Envoy has several modes by which it can learn about the world. The most basic is a static configuration file which requires you to know in advance where and what the cluster definitions will be like. This tends to work well for proxies and slow-moving external vendors and the like, but is a poor choice for a dynamic, scheduled environment. On the opposite end of the spectrum Envoy supports HTTP APIs that it will reach out to periodically to perform several operations:
- Learn about all the available clusters - this is called CDS.
- Given a closer name, resolve a set of IP addresses with an optional set of zone-weighting so Envoy can have routing bias to the most local providers first - this is called SDS
- Fetch a configuration about a
route, which can alter the way a certain cluster or host is handled for circuit breaking, traffic shifting or a variety of other conditions. This is called RDS.
Envoy provides these API hooks so that it is inherently non-specific about how discovery information is provided in a given environment. Envoy never announces itself - it is instead a passive listener about the world around itself, and with a few lines of code we can provide the APIs needed to make a thin intermediate system that converts the Consul API into the Envoy discovery protocol.
Regardless wether you supply your own xDS implementation or use the off the shelf one provided by Lyft (be aware that there is a more principled gRPC protocol in the works with envoy-api), the design for how you’re going to run your containers with Envoy on Nomad is probably more interesting. The next few subsections consider the various alternative designs with a short discussions on the pros and cons of each.
Embedded Envoy
The most obvious way to deploy Envoy would be to simply have it embedded inside your application container and run a so-called “fat container”, with multiple active processes spawned from a supervising process such as runit or supervisord.
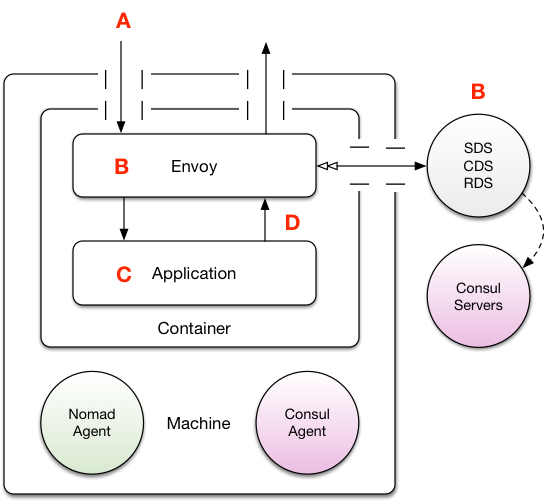
Let us consider the upsides:
-
Lazy ease. This is the simplest approach to implement as it requires very little operations work. No special Nomad job specs etc… just bind some extra ports and you’re done.
-
SSL can be terminated inside the exact same container the application is running in, meaning traffic is secure all the way until the loopback interface.
-
Inbound and outbound clusters are typically know a-priori (i.e. who will Envoy route too), so this could be configured ahead of time with a static configuration.
The downsides:
-
Upgrading across a large fleet of applications may take some time as you would have to get all users to upgrade independently. Whilst this probably isn’t a problem for many organizations, in exceedingly large teams this could be critical.
-
Application owners can potentially modify the Envoy configuration without any oversight from operations, making maintenance over time difficult if your fleet ends up with a variety of diverging configurations and ways of handling critical details like SSL termination.
There are a variety of reasons that many people do not favor running multi-process containers operationally, but none the less it is still common. This tends to be the easiest approach for users who are transitioning from a VM-based infrastructure.
Host-based Envoy
As Envoy can be considered a universal way of handling network operations in the cluster, it might be tempting to consider deploying Envoy on every host and then having containers route from their private address space to the host and out to the other nodes via a single “common” Envoy per-host.
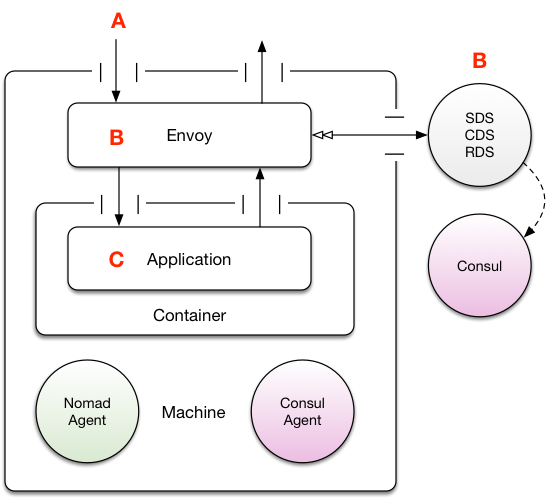
The upsides here are:
-
Fewer moving parts operationally: you only have as many Envoy instances as you have hosts.
-
Potential for more connection re-use. If each host in the cluster has a single Envoy, and there’s more than a single application on each node, then a higher probability exists that there exists a higher chance for SSL keep-alive and connection re-use, which - potentially - could reduce latency if your request profile is quite bursty as you would not be constantly paying SSL session establishment costs.
The downsides are:
-
SSL termination is not happening next to the application. In an environment that is in anyway non-private (perhaps even across teams within a large organization) it might be undesirable - or indeed, too risky, depending on your domain - to terminate the SSL of a request “early” and continue routing locally in plain text.
-
Potentially negative blast radius. If you run larger hosts machines for your Nomad workers, then they can each accommodate more work. In the event you loose the Envoy for a given host (perhaps it crashed, for example) then every application on the host looses its ability to fulfill requests. Depending on your application domain and hardware trade-offs, this might be acceptable, or it might be unthinkable.
-
Maintenance can be difficult. Patching such a critical and high-throughput part of the system without an outage or affecting traffic in anyway is going to be exceedingly difficult. Unlike the Nomad worker which can be taken offline at runtime and then updated, allowing it to pickup where it left off, Envoy has active connections to real callers.
Whilst i’ve never seen this design in the field, this is not dissimilar to how Kubernetes runs kube-proxy. If you have a completely trusted cluster the security concerns could be put aside and, potentially, this design could work well as it is operationally simpler. It does however come with some unknowns, as Envoy is expecting to be told the node address and cluster for which it is logically representing, at the time Envoy boots.
Task Group Envoy
In Nomad parlance, the job specification defines two tasks to be spawned within the same task group; your application container, and an Envoy container. This patten is often used with logging side cars, but can happily be adapted for other purposes. In short, being in the same task group means Nomad will place those tasks on the same host, and then propagate some environment variables into each task member about the location (TCP ports, as needed) of the other container. Some readers might draw a parallel here to the Kubernetes Pod concept.
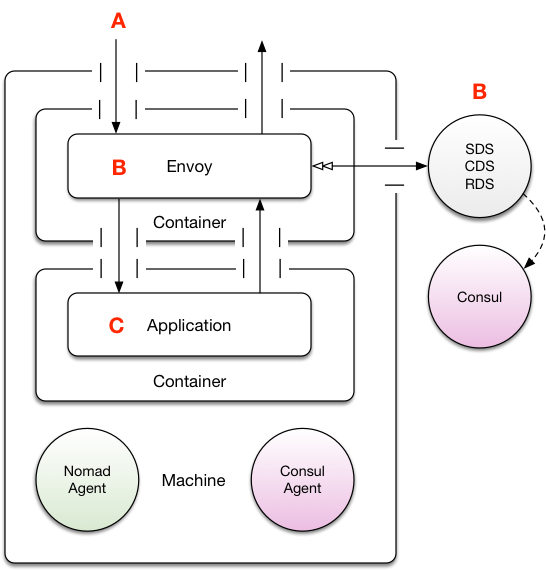
The upsides here are:
-
Global maintenance is easy. If you want to modify the location of your xDS systems, or SSL configuration then you simply need to update the Envoy container and you’re done without having to engage application development teams.
-
Mostly the same runtime properties as the embedded design
The downsides are:
- Operationally a little more complicated as there are important details that must be paid attention too. For example, when submitting the task group, setting the application task as the “leader” process so that the companion containers get cleaned up is really important. Without this you will leak containers over time and not realize.
This is perhaps the most interesting design within the article, as it represents an interesting trade off between host-based and embedded deployment models. For many users this could work well.
Conclusions
In this article we’ve discussed how Envoy, Nomad and Consul can be used to deploy containerized applications. Frankly, I think this is one of the most exciting areas of infrastructure development available today. Being able to craft a solution using generic pieces which are awesome at just one thing goes to the very heart of the unix philosophy.
Whilst the solutions covered in this article are not zero-cost (I don’t believe that solution will ever exist!), they do represent the ability to enable fast application development and evolution, whilst lowering overall operational expenditure by providing a converged infrastructure runtime. Moreover, the advent of broadly available commodity cloud computing has forced a refresh in the way we approach systems tooling; traditional methodologies and assumptions such as hardware failing infrequently no longer hold true. Applications need to be resilient, dynamically recovering from a variety of failures and error modes, and infrastructure systems must rapidly be improved to build platforms that development teams want to use: Nomad, Vault, Consul and Envoy represent - in my opinion - the building blocks for these kinds of improvements.
If you liked this article, but perhaps are interested or committed in alternative components for the various items listed here, then consider these options:
Schedulers
Coordination
Routing
Thanks for reading. Please feel free to leave a comment below.